
Medicína na hlubokém webu
Medicine on the invisible web
The term “invisible web” was used for the first time in 1994 by American specialist Jill Ellsworth. She coined this expression for the kind of information that was not accessible by using the search engines of the time. Nowadays the Internet is divided into two parts – on the one hand the visible and surface web and on the other hand an up to 500 times larger and invisible, opaque or deep web. It is in this invisible web that a large quantity of valid medical data is to be found. This paper contains some links to several sources.
Key words:
invisible web, medical information, searching.
Authors:
J. Menoušek
Authors‘ workplace:
Emeritní vedoucí střediska vědeckých informací NsP Louny
Published in:
Prakt. Lék. 2012; 92(3): 136-138
Category:
Reviews
Overview
Pojmu „neviditelný web“ použila v roce 1994 poprvé americká odbornice Jill Ellsworthová. Označila tak informace, které nebylo možné na internetu najít pomocí tehdejších vyhledávačů. Internet je dodnes rozdělen na dvě části: na jedné straně viditelný a „brouzdatelný“ web a na druhé straně až 500 krát větší neviditelný, neprůhledný či hluboký web.
Právě v něm se nachází i mnoho validních medicínských informací. Součástí článku jsou i odkazy na některé zdroje.
Klíčová slova:
neviditelný web, lékařské informace, vyhledávání.
Povrchový (viditelný, indexovatelný, „surfovatelný“) web
Na internetu můžeme nejsnáze najít informace, které jsou dostupné přímo buď pomocí různých tzv. katalogových vyhledávacích serverů – hledáme v předmětově uspořádaných rubrikách, kterých může být v krajním případě i přes milion (viz. např. vícejazyčný a dosud snad nejrozsáhlejší „ručně“ budovaný internetový seznam www.dmoz.org ) – nebo častěji pomocí tzv. fultextových vyhledávačů (slova nebo slovní spojení server hledá a indexuje přímo v plných textech hledaných dokumentů). Existují i tzv. hybridní vyhledávače, používající obě metody.
Mezi všeobecně nejpoužívanější vyhledávací služby (search engines) u nás patří i nám asi nejznámější www.google.cz nebo www.seznam.cz.
Takto snadno a rychle vyhledané stránky mají většinou veřejný charakter, největším problémem – doslova skrytým Damoklovým mečem – občas bývá jejich pochybná validita. V oblasti medicínských informací může jít nejen o zdraví, ale v některých případech dokonce i o život (7).
Další velké množství informací je na internetu přístupné zprostředkovaně (vlastně už tady můžeme začít hovořit o více či méně „neviditelném webu“). Obvykle jde o profesionální, často na komerční bázi organizovaná databázová centra. Internetové prostředí je využíváno jako jedna z metod přístupu. V našem případě jde většinou o různé servery, na kterých se obvykle po nezbytné registraci (ty bývají ještě dostupné zdarma), ale často teprve až po zaplacení předplatného, nebo nějakého jednorázového poplatku, dostaneme např. k elektronickým kopiím plných textů (proto hovoříme o tzv. fulltextových databázích) článků různých renomovaných, a tudíž i recenzovaných klasických tištěných odborných medicínských časopisů. Pro ukázku nemusíme chodit daleko – patří sem i Praktický lékař (9). Ale pozor – dnes už vznikají i ryze elektronické časopisy, které nemají tištěnou verzi!
Dalším příkladem mohou být některé tzv. faktografické databáze, které obsahují jednotně strukturované informace např. o lécích, zdravotní bezpečnosti chemických sloučenin (viz např Material Safety Data Sheet (6), aj.
V rešeršní práci se prakticky neobejdeme bez tzv. bibliografických databází, které většinou obsahují pouze záznamy článků či publikací, často formou citací a údajů o jejich obsahu – viz např. velmi cenný a volně přístupný PubMed (Medline) (11), v němž se ale můžeme v některých případech přímo dopracovat i k plným textům článků. Nebo i méně známou a bohužel často neprávem opomíjenou komerční bibliografii EMBASE (Excerpta Medica) (5), která mimochodem monitoruje i články, uveřejněné zde v Praktickém lékaři.
Validita těchto zdrojů je většinou vysoká, problém ale obvykle bývá s obtížnou dostupností cílových materiálů. Kompromisním východiskem může být např. tzv. vzdálený přístup pro klienty velkých lékařských knihoven (ale až po zaplacení ročního čtenářského poplatku). Tyto knihovny obvykle nakupují (za použití dotací z veřejných zdrojů) licence pro on-line přístup do různých podobných komerčních informačních center a významnou měrou tak napomáhají rozvoji nejen vzdělávání, ale i vědeckého výzkumu. Seznam těchto bohulibých knihoven, jakož i přehled databází, dostupných pomocí této užitečné služby, získáme na webu pražské Národní lékařské knihovny (10), pro zajímavost si můžeme prohlédnout i portál všech elektronických zdrojů Univerzity Karlovy (1).
Kolik existuje stránek „povrchového“ webu, nelze dost dobře přesně zjistit, a proto se odhady často rozcházejí (4). Podle jednoho z renomovaných pramenů (12) jich v únoru 2012 bylo kolem 55 miliard. To vše je ale pouze viditelná část ledovce (obr. 1).
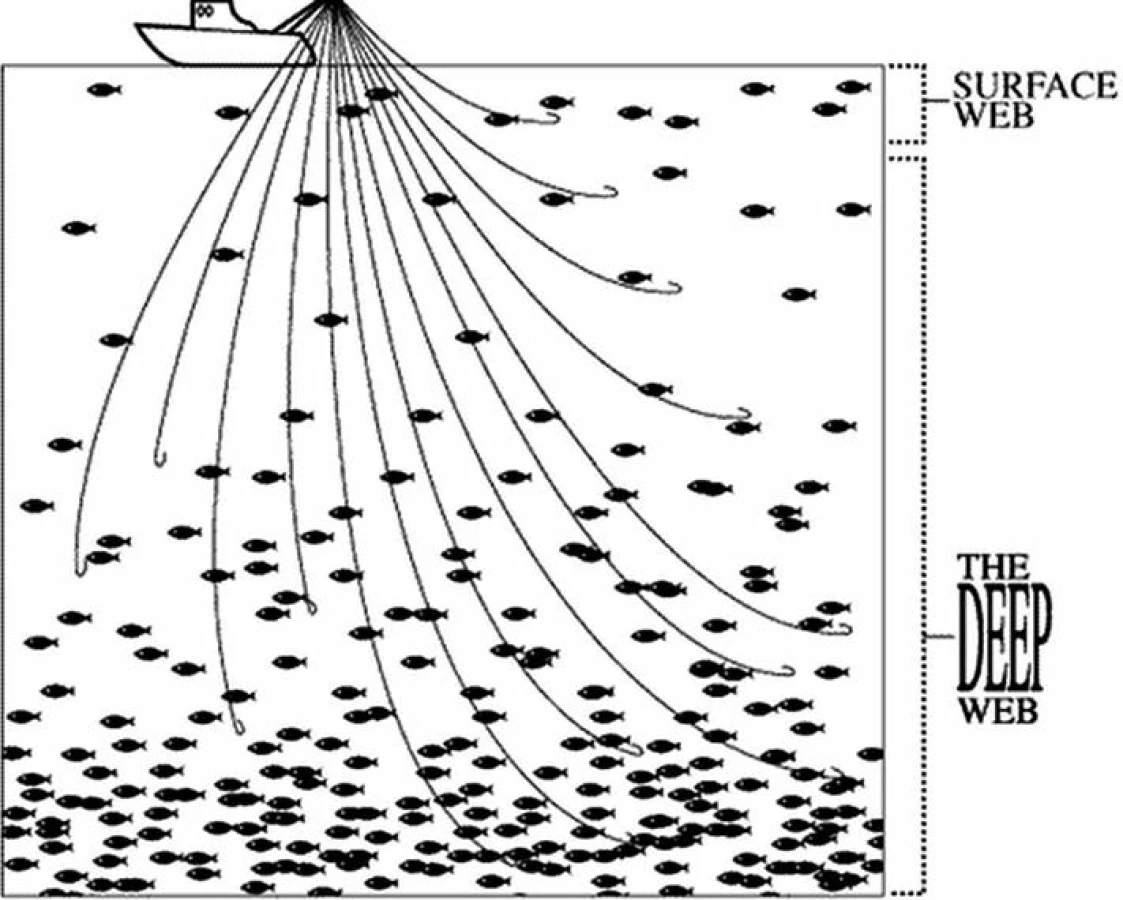
Ale i toto přirovnání pokulhává. Zatímco ledovec pod hladinou je asi devětkrát větší než jeho viditelná část, tzv. neviditelný web je dokonce cca 500 x větší (3), než ten, který můžeme prozkoumávat pomocí běžných vyhledávačů. Odhaduje se, že v oblasti hlubokého webu je přibližně 350 tisíc (!) databází, (z toho asi 150 000 s jedinečným obsahem), které nejsou dostupné běžným vyhledávačům (2).
Je logické, že v tomto ohromném oceánu se skrývají i velmi cenné informace, včetně těch, které se dají využít v medicíně.
Hluboký (neviditelný, skrytý, neprůhledný) web
V devadesátých letech minulého století se začala v internetovém prostředí uplatňovat dnešní nejrozšířenější služba sítě – WWW (World Wide Web). Nechce se věřit, že ještě roce 1993 tuto službu využívalo na celém světě pouhých 50 serverů (!). Již o rok později však americká odbornice Jill Ellsworthová použila poprvé pojmu „invisible web“ (neviditelný web). Označila tak informace, které nešlo na síti najít pomocí výše zmíněných search engines (které tehdy byly také v plenkách).
Proč nejsou některé stránky viditelné?
V zásadě platí, že proto, aby mohla být nějaká stránka nalezena, musí na ni odkazovat jiné stránky. Robotické programy, tzv. spidery a crawlery, fungují na principu “nalézání cesty” (path finding). Každá stránka, která má být archivována pro pozdější prohledávání, musí být nejprve objevena, tzn. musí k ní vést viditelná stezka z jiné webové stránky. Pokud tato cesta chybí (stránky jsou tzv. odpojené, nebo jde o tzv. samotáře, které nemají odkazy na jiné a na které také není odkaz) je velká část webu pro crawlery neviditelná a nemůže jimi být dosažena, a tudíž ani archivována. Tato část webu je nazývána hluboký nebo skrytý web.
Dalším důvodem může být např. i to, že vyhledávací stroje jsou zpravidla optimalizované na textové dokumenty. Pokud tedy stránka obsahuje hlavně obrázky, video a audio, nedostatek textu způsobí, že robot jako by „neporozumí“ obsahu. Velmi častá situace nastává, kdy robot by dokázal obsah indexovat, ale správce stránky mu to neumožňuje – je zapotřebí udat uživatelské jméno a heslo.
K absolutně „neviditelným“ stránkám patří ty, kde roboty nedokážou indexovat určité druhy souborů (např. pdf, rtf, flash, komprimované soubory, postscript, apod.) prostě proto, že na to nejsou, např. z ekonomických důvodů, vůbec naprogramované. Dále nejsou pro search engines dostupné např. také stránky s tzv. dynamicky vytvářeným obsahem (generují se dočasně až na základě momentálního požadavku uživatele), atd. (8). Kdybychom tuto velkou část hlubokého webu přirovnali k lidskému mozku, je to vlastně, jako kdybychom trpěli těžkou sklerózou. Informace tam kdesi jsou, ale člověk se k nim nemůže dostat, neumí si je vybavit.
Musíme ale říci, že nedostupnost hlubokého webu pro roboty je čistě technický a relativní problém. Hranice mezi tím, co je a není dostupné (viditelné), se neustále mění a posunuje oběma směry v závislosti na tom, jak se vyvíjejí technologie webu i automatických robotů, jakož i ekonomické zájmy provozovatelů vyhledávacích služeb. Některé z nich např. řadí velké množství nalezených výsledků tak, že v úvodu indexu odkazů zobrazuje ty stránky, které byly v minulosti nejvíce žádány a hledány jinými uživateli (viz Google). Takže ta „naše“ hledaná stránka může být obecně „méně zajímavá“, a tak může být uvedena až někde jako tisící v pořadí (tedy prakticky se pro nás stává vlastně „neviditelná“).
Jak nahlédnout do hlubokého webu?
Pokud hledáme např. hodně „vousaté“ a již dávno smazané a zdánlivě nedostupné stránky, můžeme se při léčbě „sklerózy“ tzv. podívat do notýsku, neboli pokusit se využít tzv. webového archivu. Tam jsou uloženy kopie stránek, které byly nalezeny roboty kdysi v minulosti, ale majitelé těchto archivů se rozhodli je nesmazat. U nás to je např. www.webarchiv.cz, velmi zajímavý je světový archiv, dostupný službou pod názvem WayBackMachine (13). V tomto zajímavém archivu můžeme např. snadno a „na první pokus“ najít, jak spartánsky vypadaly „nejstarší“ stránky Seznamu, zachycené robotem 14. listopadu 1996.
Ale vraťme se k medicíně.
Nejlépe asi bude, když si problematiku tzv. hlubokého webu ukážeme na nějakém modelovém příkladu. Budeme např. hledat materiály, respektive bibliografické informace, na téma využití hormonu melatoninu pro léčbu nespavosti. Jako filtr si stanovíme požadavek, aby se obě klíčová slova (melatonin, insomnia) současně vyskytovala přímo v názvu dokumentu.
Nejprve použijeme rešeršéry nejpoužívanější a již zmíněnou databázi Pubmed z dílny Národní lékařské knihovny USA. Našemu požadavku (cit. 20. 2. 2012) bude vyhovovat celkem 71 záznamů (15 z nich dostupných přímo v plném textu).
A nyní využijeme některých možností, které nám skýtá tzv. hluboký web. Záměrně neuvádím termín „neviditelný“ web, protože některé výsledky bychom dříve či později možná nalezli i pomocí klasických vyhledávačů, ovšem skryté či upozaděné a jinak zastrčené.
Dále proto uvádím přehled některých vyhledávačů (představme si je jako sítě), vhodných pro různé hloubky oceánu, nazývaného „hluboký web“. Určité služby umožňují zadat dotaz přirozeným jazykem, jiné vyžadují aplikaci běžně používaných logických operátorů AND, OR, NOT, nebo umožňují hledat v názvu přesné slovní spojení – „frázi“. Některé vyhledávače umí v rámci tzv. „advanced search“ (postupného, pokročilého, rozšířeného) vyhledávání dokonce hledat v určitých polích, včetně např. v námi požadovaném „názvu článku“ (u takových uvádím pro zajímavost a pro srovnání v závorce počet výsledků při aplikaci našich modelových klíčových slov „melatonin“ a „insomnia“.

Závěr
Celý tento článek jsem napsal zejména proto, abych upozornil, že k validní rešeršní práci nestačí umět pouze vyhledávat v Pubmedu a v Google. Na internetu lze rozhodit sítě tak, abychom ulovili i chutné ryby nejen u hladiny, ale i z větších hloubek. Není to vždy práce jednoduchá a může být občas i poněkud zdlouhavá. Neexistuje také žádný jednoduchý návod, nebo kuchařka typu „krok za krokem“, jak informaci získat. Platí, že hledání (searching) musíme tak trochu atavisticky zaměnit za lov (hunting). Někdy může být taková praxe docela zajímavá, a pokud se nám podaří chytit dlouho hledanou Bílou velrybu, potom i vzrušující.
Přeji Petrův zdar!
Jiří Menoušek
Žižkova 351
43907 Peruc
E-mail: jiri.menousek@tiscali.cz
Sources
1. Abecední seznam zdrojů. Portál elektronických zdrojů Karlovy Univerzity [on line]. [cit. 2012-02-20]. Dostupný z WWW: http://bi.cuni.cz/prehled/abecedne.php?lang=cs.
2. Bergman, M.K. Guide to Effective Searching of the Internet. 2005, [on line] [cit. 2012-02-20]. Dostupný z WWW: http://brightplanet.com/images/ uploads/SearchEngineTutorialFormatted041218.pdf.
3. Bergman, M.K. The Deep Web: Surfacing Hidden Value. 2009. [on line] [cit. 2012-02-20]. Dostupný z WWW: http://www.brightplanet.com/images/ uploads/DeepWebWhitePaper_20091015.pdf.
4. Coufal, L. Web po 20 letech : co z něj zbude pro budoucí generace? Knihovna 2009, 20(2), s. 17-32. Dostupný také z WWW: http://knihovna.nkp.cz/knihovna92/0902097.htm [cit. 2012-02-20].
5. Excerpta Medica [on line] [cit. 2012-03-18]. Dostupný takéz WWW: http://www.excerptamedica.com
6. Material Safety Data Sheets - OHS. AIP. Produkty a služby. [on line] [cit. 2012-02-20]. Dostupný také z WWW: http://www.aip.cz/titul.php?titul=967
7. Menoušek, J. Validita medicínských informací na internetu – věčně visící Damoklův meč? Prakt. lék. 2011, 91(4), s. 230-231.
8. Neviditelný web. Infogram [on line] [cit. 2012-02-20]. Dostupný z WWW: http://www.infogram.cz/article.do?articleId=1765
9. Praktický lékař. Časopisy ČLS JEP [on line] [cit. 2012-02-20]. Dostupný také z WWW: http://www.prolekare.cz/prakticky-lekar
10. Přístupy k profesionálním informačním zdrojům ve zdravotnictví v České republice a USA. Národní lékařská knihovna. [on line] [cit. 2012-02-20]. Dostupný z WWW: http://www.nlk.cz/sluzby/pruvodce/pristupy-k-profesionalnim-zdravotnickym-informacnim-zdrojum-v-knihovnach-cr-1
11. Pubmed. National Library of Medicine. [on line] [cit. 2012-02-20]. Dostupný z WWW: http://www.ncbi.nlm.nih.gov/pubmed/
12. The size of the World Wide Web. [on line] [cit. 2012-02-20]. Dostupný z WWW: http://www.worldwidewebsize.com
13. WayBackMachine. [on line] [cit. 2012-02-20]. Dostupný z WWW: http://www.archive.org/web/web.php.
Labels
General practitioner for children and adolescents General practitioner for adultsArticle was published in
General Practitioner

2012 Issue 3
- Advances in the Treatment of Myasthenia Gravis on the Horizon
- Hope Awakens with Early Diagnosis of Parkinson's Disease Based on Skin Odor
- Memantine in Dementia Therapy – Current Findings and Possible Future Applications
- Memantine Eases Daily Life for Patients and Caregivers
- Possibilities of Using Metamizole in the Treatment of Acute Primary Headaches
Most read in this issue
- Mikrolitiáza varlete
- Ošetřovatelské intervence v domácí péči
- Vliv stárnutí na kognitivní funkce a možnosti hodnocení v terénní praxi
- Praktický lékař a rehabilitace