
Statistika v biomedicínském výzkumu I
Statistics in biomedical research I
Statistics are increasingly prevalent in medical practice. Nowadays much concern is devoted in hospital utility statistics, audit, resource allocation, number of new cases (for example AIDS), and so on. Journals nad magazines for doctors are full of statistical material of this sort, as well as the finding of individual research studies. Statistical issues are implicit in all clinical practice when making diagnosis and choosing an appropriate treatment. It is increasingly common to see statistical result from research papers quoted in promotional materiál for drugs and other medical therapies.
The article focuses on particular steps of a research project – planning, design, data collection and data storage, data processing, data analysis, presentation, interpretation and publication of results. We deal with planning, design and data storage in the first part of Statistics in biomedical research. Particular attention is paid to the role of prior estimates of a sample size. Using examples it is showed a relationship among a mean difference, a variability, a sample size and a statistically significance in continuous data. It is demonstrated an association among an occurrence of a certain quality in two samples, sample sizes and a significance in qualitative data. It is explained the difference between clinical and statistical significance. There are practical advices how to store data correctly for statistical processing.
Keywords:
statistics – research project – planning – sample size estimation – data storage
Autoři:
K. Langová
![]() ; J. Zapletalová; L. Ličman
; J. Zapletalová; L. Ličman
Působiště autorů:
Ústav lékařské biofyziky, Lékařská fakulta UP v Olomouci
Vyšlo v časopise:
Anest. intenziv. Med., 27, 2016, č. 6, s. 395-399
Kategorie:
Speciální článek
Souhrn
Užívání statistiky v medicínské praxi je stále běžnější. Velký zájem je věnován zdravotnickým statistikám, auditům, počtu výskytu nových případů onemocnění (např. AIDS) a tak dále. V každém časopise pro lékaře můžeme najít podobné statistiky, rovněž zde nalézáme závěry klinických studií, které obsahují odbornou statistickou terminologii. Statistické přístupy se využívají v klinické praxi při stanovení diagnózy i výběru vhodné léčby. Stále častěji se můžeme setkat s citací klinických výzkumů v propagačních materiálech nových léků či nových medicínských metod.
Článek popisuje jednotlivé fáze výzkumného projektu – plánování, návrh, sběr a ukládání dat, zpracování dat, analýzu dat, prezentaci, interpretaci a publikaci výsledků. V první části Statistiky v biomedicínském výzkumu se zabýváme plánováním, návrhem a ukládáním dat z hlediska statistiky. Pozornost je věnována stanovení vhodné velikosti souboru. Pomocí praktických příkladů je ukázán vztah mezi rozdílem průměrů, variabilitou, velikostí souborů a statistickou významností u spojitých dat. U kvalitativních dat se obdobně demonstruje závislost mezi výskytem dané vlastnosti u dvou souborů, velikosti těchto souborů a signifikancí. Je vysvětlen rozdíl mezi klinickou a statistickou významností. V článku jsou uvedeny praktické rady, jak správně uložit data pro statistické zpracování.
Klíčová slova:
statistika – výzkumný projekt – plánování – odhad velikosti vzorku – ukládání dat
ÚVOD
Statistika je vědní obor, jehož výsledky můžeme při své práci používat prakticky denně. Neexistuje snad jediný odborný medicínský časopis, ve kterém bychom nenašli články obsahující odbornou statistickou terminologii. Často se můžeme setkat s prezentací výsledků klinického testování nového léčivého přípravku, s porovnáním různých metod léčby pacientů nebo se zprávami o incidenci konkrétní nemoci v jednotlivých regionech. Takové studie používají k vyjádření nových poznatků vždy metody statistické analýzy.
Vysoká frekvence vědeckých sdělení v odborných časopisech však u čtenářů automaticky nezajišťuje znalost jazyka statistické analýzy. Dlouholeté zkušenosti v oblasti vědeckého výzkumu a využití metod statistiky ukazují spíše na to, že mnohé statistické pojmy, respektive pojmy z výzkumu jsou i odbornou veřejností chápány nepřesně, nebo dokonce nejsou pochopeny vůbec. V takovém případě však odborná sdělení nemohou přinést předpokládaný efekt.
Vztah lékařů ke statistice je různorodý – od přezíravého postoje k naprosto nekritickému přijímání všech výsledků, u nichž je p menší než 0,05. Zastánci přezíravého postoje argumentují často citátem, který bývá mylně připisován W. Churchillovi: „Věřím jen té statistice, kterou jsem sám zfalšoval.“ Tento výrok pravděpodobně rozšířil J. Goebbels v rámci své propagandistické kampaně. Jaký tedy zaujmout ke statistice postoj? Statistika je nástroj a jako každý nástroj může být zneužit nebo se dá využít k získání nových zajímavých a užitečných poznatků. Možná si kladete otázku „Proč statistiku v medicíně potřebujeme?“ Statistika obsahuje dvě oblasti, popisnou a induktivní statistiku. Předmětem popisné statistiky je vytváření účelných sumárních přehledů, tabulek a grafů. Cíl induktivní statistiky bychom si mohli opět přiblížit citátem S. Johnsona: „Nemusíte sníst celého vola na to, abyste poznali, že maso je tuhé.“ Přeneseno do oblasti medicíny – nemusíme vyšetřit celou populaci, abychom mohli vyvodit určité závěry. Cílem induktivní statistiky je tedy zobecnit poznatky zjištěné na vzorku pacientů na celou populaci a vyjádřit stupeň spolehlivosti tohoto zobecnění.
OBECNÉ SCHÉMA VÝZKUMNÉHO PROJEKTU
Každý výzkumný projekt můžeme schematicky popsat dílčími kroky uvedenými na obrázku 1.
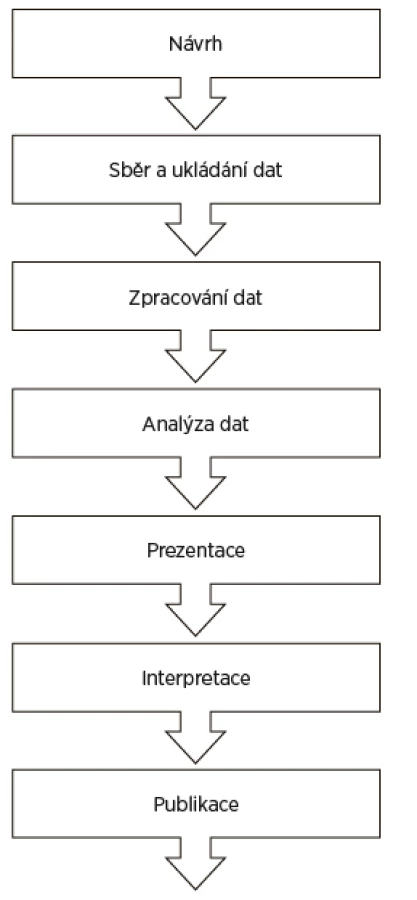
Statistický způsob myšlení může přispět ke kvalitnímu řešení výzkumného projektu prakticky v jakékoliv fázi projektu.
PLÁNOVÁNÍ A NÁVRH VÝZKUMNÉHO PROJEKTU Z POHLEDU STATISTIKA
Prvotním nejdůležitějším úkolem je přesná formulace cílů i účelu výzkumu a přesné vymezení studované populace a sledovaných znaků. Důležitým krokem je správné stanovení velikosti vzorku pro klinickou studii. Potenciální nadhodnocení počtu pacientů zařazených do studie s sebou nese vyšší ekonomické nároky. Zvyšuje se také riziko neetického vystavení zbytečně vysokého počtu pacientů nově testované léčbě se všemi s tímto souvisejícími zdravotními riziky a při neúměrně vysoké délce náběru pacientů také prodloužení doby zpřístupnění nové léčby pacientům. Naopak při podhodnocení počtu zařazených pacientů roste riziko nemožnosti prokázat statisticky relevantní závěry o vlastnostech testované léčby a tedy znehodnocení celé studie. I přesto, že problematika odhadu velikosti vzorku se může na první pohled zdát jako triviální proces, provedené analýzy publikovaných výsledků randomizovaných klinických studií opakovaně ukazují, že tento aspekt plánování studií bývá nezřídka podceněn [2]. Je proto dobré kontaktovat statistika již v této fázi výzkumu a požádat ho o odhad velikosti vzorku. Je třeba si připravit informace, které statistik potřebuje k provedení validního odhadu. Řešitel projektu by si měl uvědomit, co je jeho „cílovou proměnnou“ a jakého je typu. Pokud budeme srovnávat dva nezávislé vzorky (dvě různé skupiny pacientů) ve spojité proměnné (např. v systolickém tlaku krve), stanovíme, jaký rozdíl mezi průměry je pro nás klinicky zajímavý (např. 20 mm Hg). Dále bychom měli znát variabilitu této veličiny v populaci. Variabilitu zadáme pomocí rozptylu či jeho druhé odmocniny, tj. směrodatné odchylky (např. směrodatná odchylka = 15 mm Hg). U veličin, které byly studovány již v minulosti, můžeme využít výsledky dříve publikovaných studií.
Jestliže je sledovaná cílová veličina kvalitativního typu (např. výskyt krvácení), je třeba zadat pravděpodobnost výskytu dané vlastnosti u obou porovnávaných vzorků. Například v prvním vzorku předpokládáme výskyt krvácení u 10 % pacientů, ve druhém vzorku u 30 % pacientů.
Statistik potom doporučí jako adekvátní velikost vzorku takovou, že při dané síle testu a dané hladině statistické významnosti budou uvažované klinicky zajímavé rozdíly také statisticky významné.
Klinická versus statistická významnost
Použití slova „významnost“ vede k mnoha nedorozuměním, zda je míněna významnost statistická nebo klinická. Obvyklá praxe je pokládat statisticky významný výsledek za skutečný efekt a naopak. Tato interpretace však nemusí být nutně oprávněná. Vlivem značné velikosti zkoumaných vzorků mohou být i klinicky zcela bezvýznamné rozdíly statisticky signifikantní. Podobně není rozumné brát každý nevýznamný výsledek jako indikaci neexistence skutečného efektu jen proto, že nemůžeme zamítnout nulovou hypotézu. Je možné, že experiment měl nedostatečnou sílu způsobenou příliš malým počtem pozorování [3].
Toto je dokumentováno v tabulce 1.
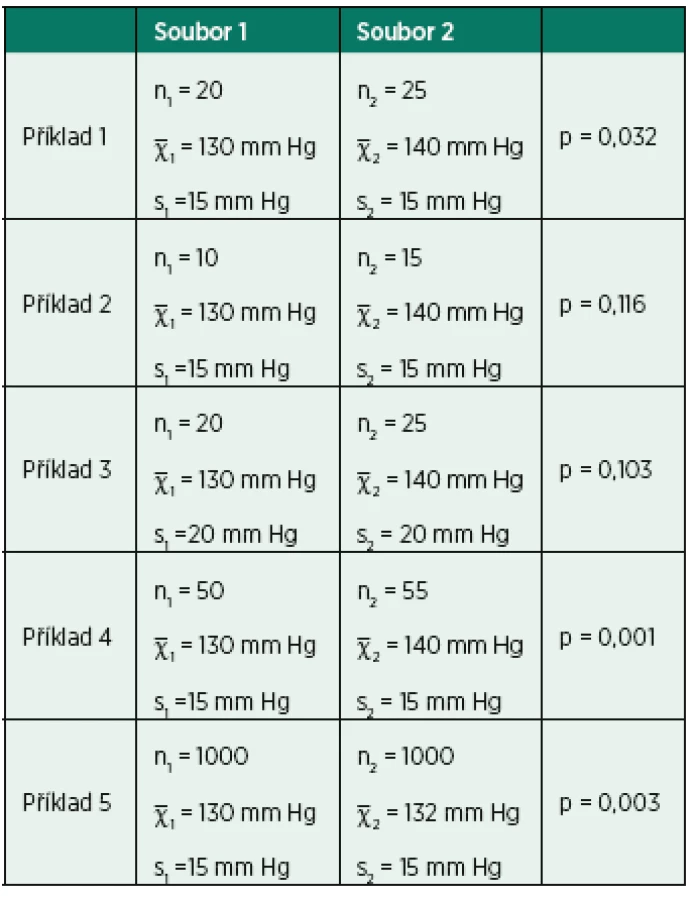
Příklad 1 dokumentuje výpočet prokazující rozdíl 10 mm Hg v průměrném systolickém tlaku mezi soubory 1 a 2 jako statisticky významný (p = 0,032).
Příklad 2 zahrnuje ten samý číselný rozdíl průměrů jako příklad 1, nicméně vzhledem k menší velikosti vzorku již neprokázaný jako statisticky významný (p = 0,116).
Příklad 3 ukazuje rozdíl v průměrném tlaku krve obou skupin lidí, který nebyl prokázán jako statisticky významný vzhledem k vyšší variabilitě měření (vyšší směrodatná odchylka ve srovnání s příklady 1 a 2.)
Příklad 4 ukazuje rozdíl v průměrném tlaku krve obou skupin lidí, který je vysoce významný kvůli velkým vzorkům.
Příklad 5 dokumentuje, že klinicky nepatrný rozdíl v průměrech (130 a 132 mm Hg) může být vysoce signifikantní, pokud je naměřen u velkého množství pacientů.
Obdobně můžeme sledovat závislost statistické významnosti na velikosti vzorku u kvalitativních dat v tabulce 2.

Příklad 1 ukazuje výpočet prokazující 30% rozdíl ve výskytu komplikace krvácení mezi soubory 1 a 2 jako statisticky významný (p = 0,034).
Příklad 2 zahrnuje ten samý procentuální rozdíl jako příklad 1, nicméně vzhledem k menší velikosti vzorku již nebyl prokázán jako statisticky významný (p = 0,115).
Příklad 3 ukazuje opět 30% rozdíl ve výskytu komplikace krvácení, který je vysoce významný kvůli velkým vzorkům.
Příklad 4 ukazuje, že klinicky nepatrný procentuální rozdíl (50% a 45%) může být signifikantní, když je naměřen u velkého množství pacientů.
Pokud jste doposud patřili mezi nekritické zastánce statistických testů, musíte být teď na rozpacích. Velikost vzorků by měla být stanovena před započetím výzkumu. Proces, kdy někdo svévolně mění například velikost vzorku, jen aby dosáhl statisticky významného výsledku, nelze označit za výzkum.
UKLÁDÁNÍ DAT
Současná statistická analýza se neobejde bez zpracování dat pomocí statistických software. Předpokladem úspěchu je správné uložení dat ve formě „databázové“ tabulky umožňující jejich zpracování v libovolné aplikaci. Neméně důležité je věnovat pozornost čištění dat předcházející vlastní analýze. Každá chyba, která vznikne a není nalezena ve fázi přípravy dat, se promítne do všech dalších kroků a může zapříčinit neplatnost výsledků a nutnost opakování analýzy. Správné a přehledné uložení dat je základem pozdější úspěšné statistické analýzy. Je proto vhodné rozmyslet si předem, jak budou data ukládána. Pokud nemáte s ukládáním dat pro účely statistického zpracování dostatek zkušeností, je vhodné v této fázi výzkumu opět kontaktovat statistika, který navrhne optimální formu databázové tabulky. Správně navržená tabulka ušetří čas při ukládání a zpracování dat. Přiblížíme si základní zásady, které bychom měli při tvorbě databázové tabulky dodržovat. Data ukládáme nejčastěji v programu Microsoft Excel. Každý řádek obsahuje základní jednotku dat, což je v naší praxi nejčastěji pacient. Statistickou jednotkou může být i laboratorní zvíře (potkan) nebo studovaný orgán (oko, kyčel, …). Každý sloupec obsahuje pouze jedinou vlastnost (jeden typ dat) identifikovaný hlavičkou sloupce (pohlaví pacienta, věk, diagnóza, …). Do prvního sloupce tabulky se zpravidla ukládají údaje identifikující pacienta – buď jméno pacienta, nebo jeho identifikační číslo (to je důležité pro případné doplňování tabulky). Data mohou být kvantitativní, ukládáme je pomocí čísel (věk, hmotnost, tepová frekvence, …). Je třeba, aby ukládané údaje byly u všech pacientů ve stejných jednotkách, tj. zaznamenáváme-li do tabulky např. délku anestezie, uvedeme u všech pacientů údaj v minutách. Dalším typem dat jsou kvalitativní data (pohlaví, diagnóza pacienta, …). Kvalitativní data můžeme ukládat textově nebo pomocí kódů. Ukládání pomocí kódů je rychlejší a umožňuje statistikovi snadnější zpracování dat. Kódování znamená, že každé kategorii kvalitativního znaku přiřadíme jeden číselný kód, např. muž = 1, žena = 2. Pokud se kategorie znaku vzájemně vylučují (tj. u pacienta lze zadat pouze jednu z těchto kategorií), můžeme znak uložit do jednoho sloupce. Je nepřípustné kombinovat v jednom sloupci číselné a textové hodnoty. Komentáře k datům je vhodné ukládat zvlášť. U textových dat je nezbytné kontrolovat překlepy v názvech kategorií. Specifickým typem dat jsou kalendářní data, u nichž je třeba zkontrolovat, zda jsou uložena v korektním formátu Datum. V případě, kdy údaj nebyl naměřen, nezadáváme do tabulky žádnou hodnotu ani žádný text, buňku necháme prázdnou. U číselných údajů používáme desetinnou čárku. Tabulka 3 ukazuje příklad dat uložených pro statistické zpracování.
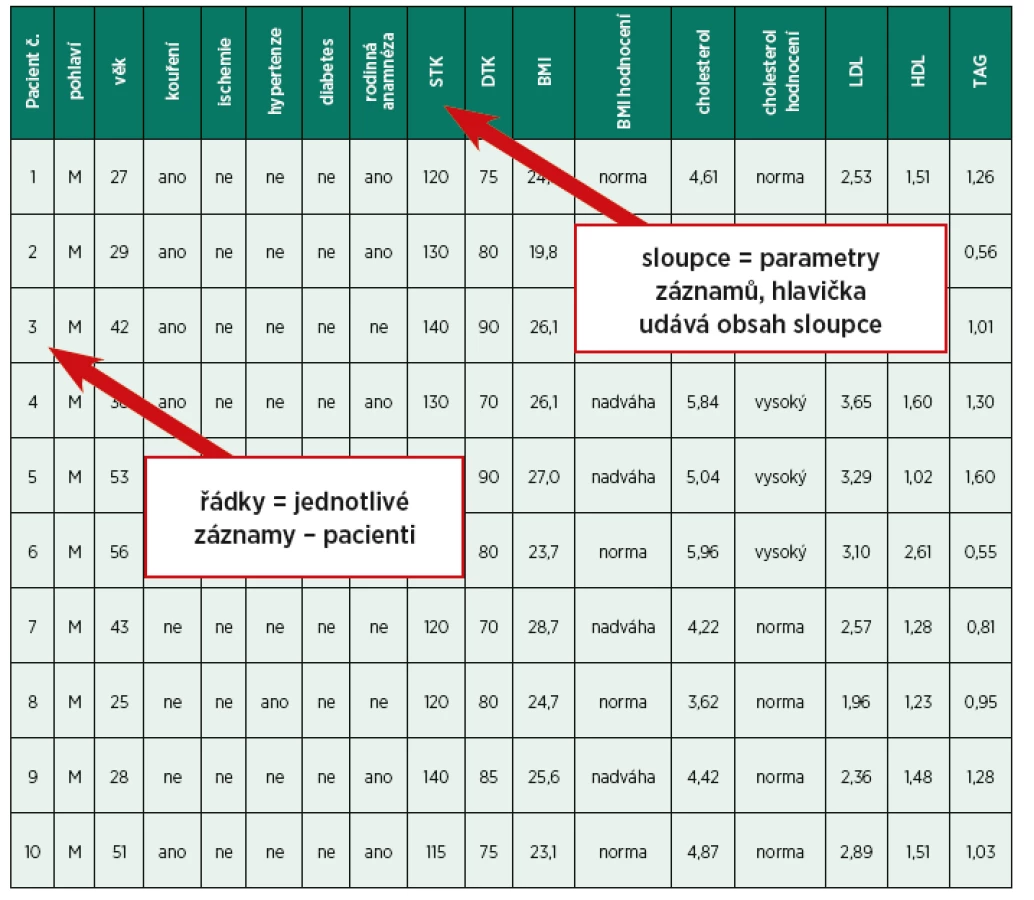
Při ukládání většího množství dat je prospěšné ukotvit první řádek a první sloupec tabulky. Ukotvení řádku s názvy měřených znaků (parametrů) a s ukotvením identifikace pacienta umožňuje pohodlné vkládání a prohlížení dat. V programu MS Excel použijeme záložku „Zobrazení“ – „Ukotvit příčky“. Také je prospěšné před předáním dat ke statistickému zpracování zkontrolovat, zda jsme omylem neuložili nesmyslné hodnoty. U dat kvantitativního typu, si můžeme zobrazit minimální a maximální hodnotu u daného sloupce. Použijeme záložku „Vzorce“ – „Vložit funkci“ – „Vybrat funkci“ MIN nebo MAX.
Je třeba si uvědomit, že i z nesmyslných dat, špatně posbíraných nebo chybně uložených, dostaneme nějaké výsledky. Platí zde pravidlo Smetí dovnitř, smetí ven (angl. Garbage In, Garbage Out – GIGO).
Poděkování
Práce byla podpořena grantovým projektem LO1304.
Autoři prohlašují, že nemají střet zájmů.
Práce byla prezentována formou přednášky na XXV. Šumperských dnech alergologie a klinické imunologie.
Do redakce došlo dne 15. 7. 2016.
Do tisku přijato dne 15. 8. 2016.
Adresa pro korespondenci:
Mgr. Kateřina Langová, Ph.D.
Ústav lékařské biofyziky Lékařská fakulta UP v Olomouci
Hněvotínská 3
775 15 Olomouc
e-mail: katerina.langova@upol.cz
Zdroje
1. Altman, D. G. Practical Statistics for Medical Research. 1. vydání, 1991, 610 s., ISBN 0-412-27630-5.
2. Kadlecová, P. Analýza vlivu designu klinické studie a vstupních předpokladů na odhad velikosti vzorku. Diplomová práce, Masarykova univerzita Brno, 2009.
3. Zvárová, J. Základy statistiky pro biomedicínské obory. 1. vydání, 2004, 218 s., ISBN 80-7184-786-0.
Štítky
Anestéziológia a resuscitácia Intenzívna medicínaČlánok vyšiel v časopise
Anesteziologie a intenzivní medicína

2016 Číslo 6
- Realita liečby bolesti v paliatívnej starostlivosti v Nemecku
- MUDr. Lenka Klimešová: Multiodborová vizita je kľúč k efektívnejšej perioperačnej liečbe chronickej bolesti
- e-Konzilium.cz — Masivní plicní embolie při tromboembolické nemoci
- Kvalita výživy na JIS a následná kvalita života spolu úzko súvisia
- DESATORO PRE PRAX: Aktuálne odporúčanie ESPEN pre nutričný manažment u pacientov s COVID-19
Najčítanejšie v tomto čísle
- Monitorování hloubky celkové anestezie
- Trombofilní stavy v těhotenství
- Regionální anestezie a léky ovlivňující hemokoagulaci – co přináší nejnovější doporučení?
-
ATESTAČNÍ OTÁZKY OBORU ANESTEZIOLOGIE A INTENZIVNÍ MEDICÍNA
Péče o pacienta po anestezii